Command line crawling with Screaming Frog SEO Spider.
Use apt-get to install Screaming Frog
-
Visit Screaming Frog's Check Updates page to identify the latest version number.
-
Update
apt-get
sudo apt-get update
- Install Screaming Frog
wget https://download.screamingfrog.co.uk/products/seo-spider/screamingfrogseospider_18.2_all.deb -P /path/to/download/dir
- Install the package
sudo dpkg -i /path/to/download/dir/screamingfrogseospider_18.2_all.deb
- Verify installation
which screamingfrogseospider
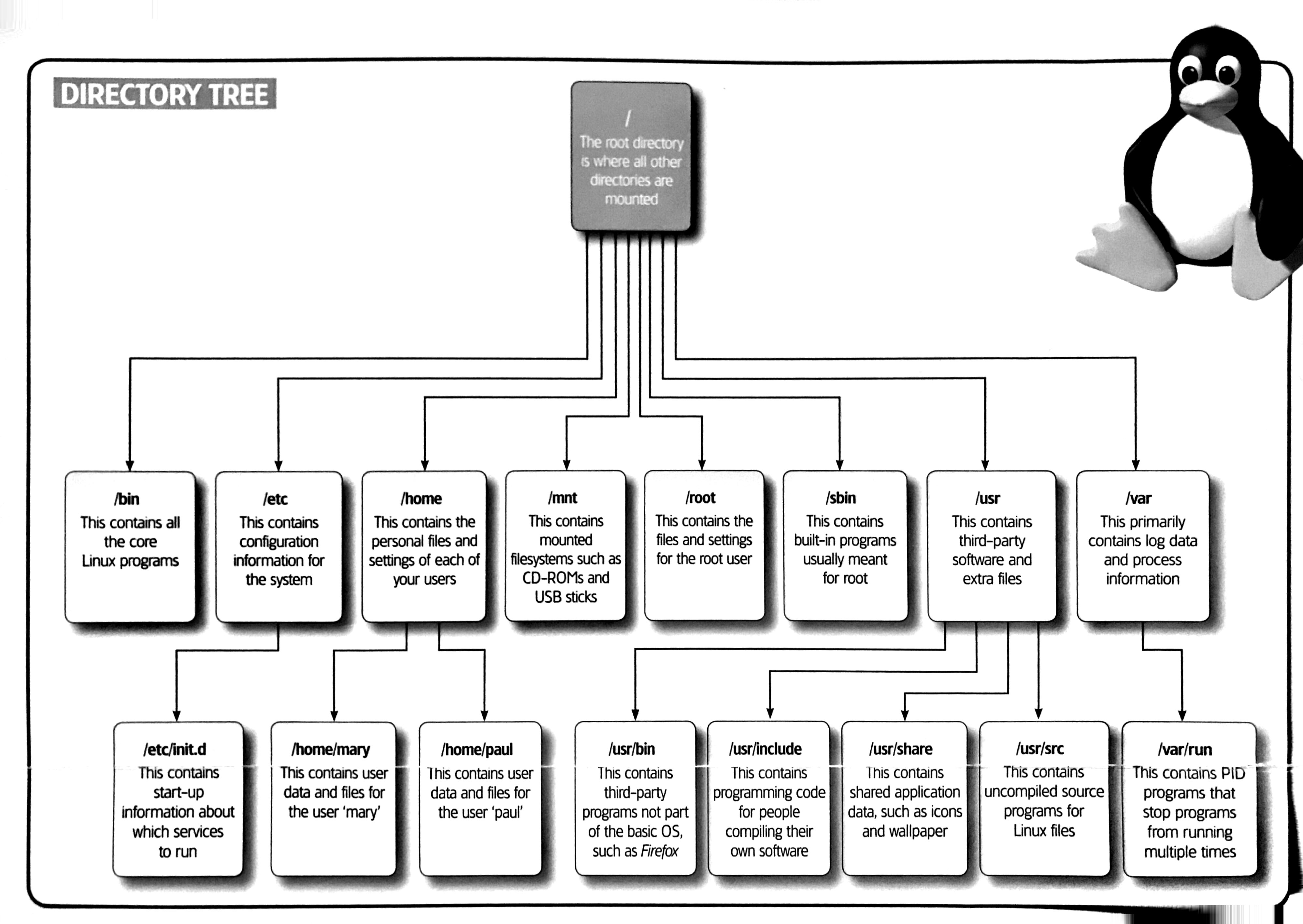
- If you're unsure where to download your package, you can always use
/usr/local/bin. I've included a diagram below to see other common places to use within the Ubuntu file directory.*
Configure
Add your paid license in headless mode.
Create a new license.txt file within a hidden directory called .ScreamingFrogSEOSpider.
sudo nano ~/.ScreamingFrogSEOSpider/licence.txt
Paste your license.
screaming_frog_username
XXXXXXXXXX-XXXXXXXXXX-XXXXXXXXXX
Accept the EULA
Create a new spider.config file within the same directory.
sudo nano ~/.ScreamingFrogSEOSpider/spider.config
Paste this acceptance agreement.
eula.accepted=11
Choose Your Storage Mode
In-Memory Mode
If you want to change the amount of memory, you want to allocate to the crawler, then create another configuration file.
sudo nano ~/.screamingfrogseospider
Suppose you want to increase your memory to 8GB. Here's the configuration detail.
-Xmx8g
If you're unsure of your available memory, try this command.
free -h
Database Mode
Your default mode is in-memory, but you might want to add a database file if you're dealing with stats like these.
Crawls < 200k URLS (8GB of RAM)
Crawls > 1M+ (16GB of RAM)
If you use a database instead of in-memory, add this to spider.config.
storage.mode=DB
Disable the Embedded Browser
Since we're working in headless mode, we'll want to disable the embedded browser.
embeddedBrowser.enable=false
Let's Start Crawling
- Create a directory for crawls
mkdir ~/crawls-2023wk08
- Minimalist example.
screamingfrogseospider --crawl https://www.chrisjmendez.com --headless --save-crawl --output-folder ~/crawls-2023wk08 --timestamped-output
About Command Line Options
There is a list of available flags. Below are required to accomplish a basic example.
--crawl
--headless is required for command line processes.
--save-crawl saves your data to a crawl.seospider.
--output-folder
--timestamped-output creates a timestamped folder for crawl.seospider helps prevent crawl collisions from your previous processes.
- Advanced Example
# screamingfrogseospider --crawl https://www.chrisjmendez.com --headless --save-crawl --output-folder ~/crawls-2023wk08 --timestamped-output --create-images-sitemap
--create-images-sitemap creates a sitemap from the completed crawl.
Resources
URLs
Diagrams


Curated List of web scraping tools for NodeJS
Curated list of web scraping tools for NodeJS developers.