
I'm working on a few big data projects and before I start writing about them, I thought I'd first write about my reflections on big data in general. I'm hoping it will provide some context for future posts.
These are my personal notes on how I think about data today now that I've been working with AWS Kinesis, Kinesis Agent, Kinesis Firehose, Redshiftc Quicksight and from the perspective of a software engineer, technical project manager and product strategist.
When Can We Call a Dataset Big Data?
If you're not sure whether your problem is a data problem or a big data problem, here are two characteristics of the latter.
Dataset Size
Data becomes "big data" when datasets are so large that they are difficult to:
- Collect
- Store
- Organize
- Analyze
- Move
- Share
The Three V's
You have big data problem when the data outgrows your ability to process information due to:
- Velocity
- Volume
- Variety - The types of data that you're dealing with.
Why Does Big Data Matter?
Every business is becoming a software-based business and one way to maintain a competitive advantage is to use analytics and insights to create leverage. Therefore, before an organization can find any benefit from computer-assited decision making (such as machine learning or AI), we first need to accomplish two tasks:
- As managers, we must use our deep industry knowledge to ask smart questions that can help us grow our business.
- As data engineers, we must first prepare our datasets in a way that can be processed. This preparation is often called "building a data pipeline".
Since you can't do one task without the other, the best thing to do is to first start creating a pipeline for data to be collected, stored, organized, analyzed, moved and shared into information, knowledge and insights. These are key steps to creating an ETL.
Data by itself often has little value. It often needs to be processed from raw bytes into something meaningful. For example, this little chart does a great job of showing how data can be converted into knowledge and later actionable insights.

If you think about it, this is a very expensive process.
"From an economic perspective, if the knowledge needed to solve the problem is readily available for free, the value of you having that knowledge yourself is effectively zero."
What are Examples of Big Data Sources?
There are two big sources of big data, computer-generated data and human-generated data.
Computer-generated Data
Examples of computer-generated data include:
- Application server logs such as Apache logs.
- Sensor data: weather, water, smart grids.
- Images and videos: traffic cameras, security cameras.
You can often use computer-generated data to track the health of an application or service.
If you're looking for a book of handy computer-created data sources, try this one
Human-generated Data
Examples of human-generated data include:
- Blogs
- Reviews / Comments
- Emails
- Pictures (selfies)
- Voice (audio chats)
- Social media engagement (likes, shares, reposts, retweets)
- Brand management
Human-generated data includes topics like natural language processing, sentiment analysis and reviews or recomendations.
What Does a Big Data Pipeline Look Like?
The pipeline below shows how data can processed into meaningful insights.
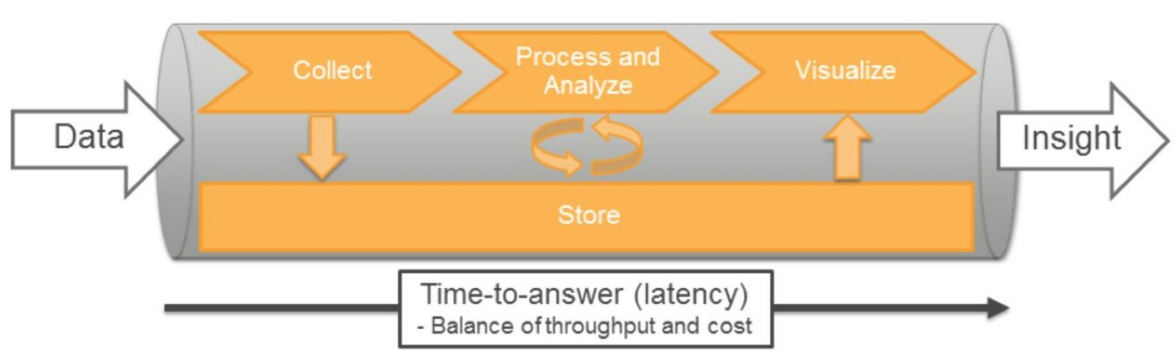
Data => Collect => Process and Analyze => Visualize => Insights
=> Store =>
Do I Have to Prepair My Data Beforehand to Later Process It?
No, not really. For example, if your finance team still uses Excel and your marketing team uses Acess and the membership team uses MySQL and the product team uses Google Analytics and you want to somehow process it, then you've got a data lake problem. Data Lake problems are great because the paradigm has been written about extensively online.
What Do You Need to Create a Pipeline?
Picking the Right Tool for the Job
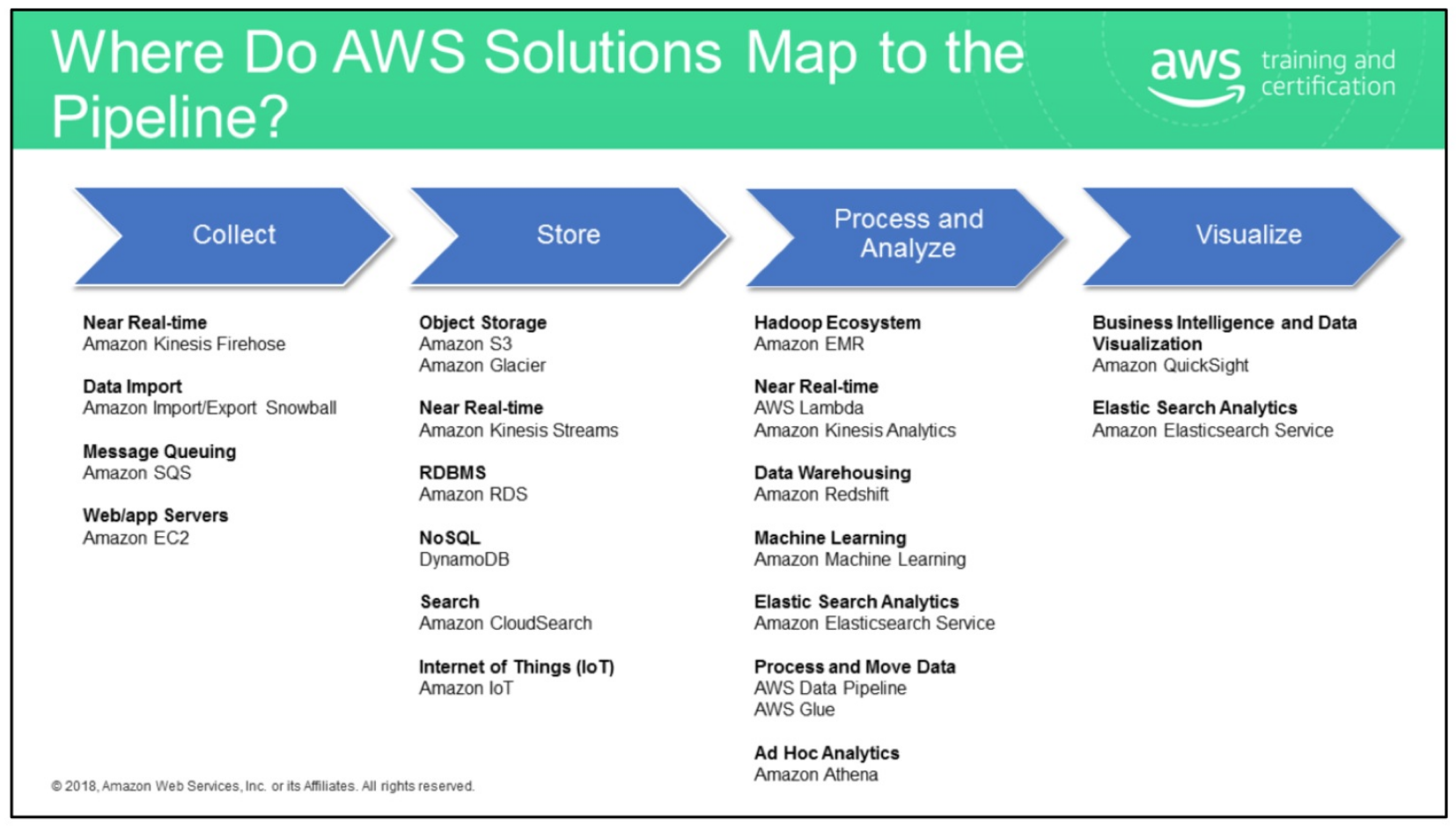
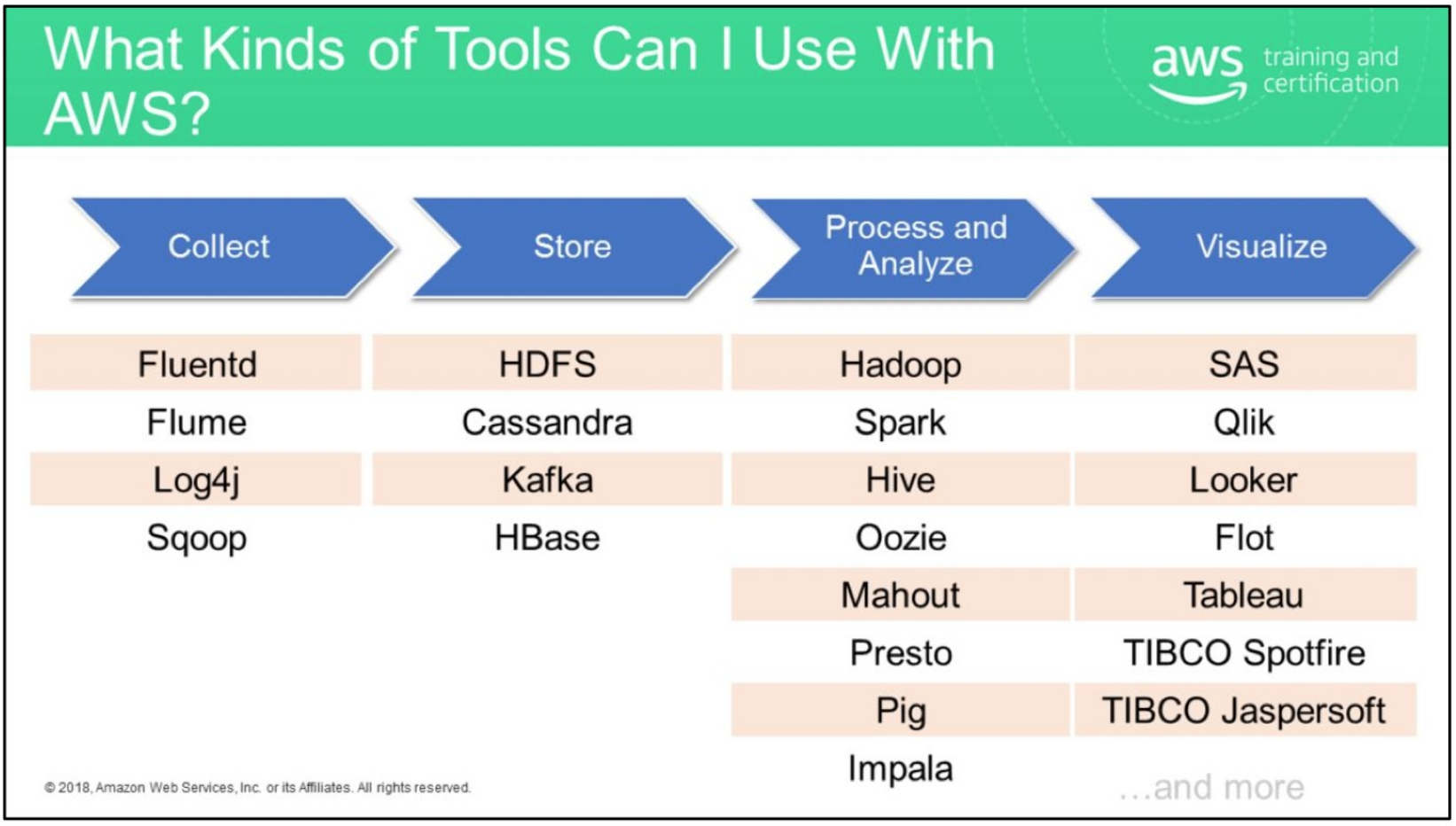
There are tons and tons and tons of products and services that can help you complete your big data pipeline. Below are two useful diagrams that itemize the products by stage.
The nice part is that you don't have to get locked into a one-size-fits-all solution. Thos type of decoupled data pipeline allows you to have multiple processing apps read-from or write to multiple data stores.
AWS Solutions
Non AWS Solutions
Good Pipeline Questions to Ask
- What is the structure of your data. Is it structured? Is this a Data Warehouse problem or a Data Lake problem?
- What is your latency? Do you need the data to be refreshed by the day? hour? minute? or second? The lower the latency, the more expensive it gets.
- What's the throughput of the data coming in? Is it a batch? A firehose?
- How are people going to access the data? Through a web portal? A visualizer?
Resources


Deploying Rails 5.x on AWS ElasticBeanstalk using AWS CodeCommit
How to deploy your Rails app on ElasticBeanstalk (including S3 buckets, security groups, load balancers, auto-scalling groups and more) using CodeCommit.